Publications
HomeNo publications found
Your search and filter combination didn't match any publications.
Try these suggestions:
- • Remove some filters to broaden your search
- • Check for typos in your search query
- • Use fewer, more general keywords
147 publications available without filters
-
Key Tax Issues at Year End for Real Estate Investors
Published 12 Dec 2025 · pwc
PwC highlights year-end tax planning opportunities for real estate investors including depreciation timing and portfolio restructuring.
executive -
Global Insurance Run-off Survey
Published 12 Dec 2025 · pwc
PwC survey examines insurance run-off market trends, capital requirements, and regulatory challenges across global jurisdictions.
executive global -
Global M&A trends in financial services: 2025 outlook
Published 12 Dec 2025 · pwc
PwC identifies key M&A trends for financial services in 2025, including digital transformation drivers and regulatory impacts on deal activity.
executive global -
Global M&A industry trends in real estate: 2025 outlook
Published 12 Dec 2025 · pwc
PwC's 2025 real estate M&A outlook examines sector trends, deal drivers, and market conditions affecting property investment transactions.
executive global -
6th Annual Global Crypto Hedge Fund Report
Published 12 Dec 2025 · pwc
PwC's 6th annual crypto hedge fund survey reveals industry trends across AUM, performance, and regulatory challenges in 2024.
executive global -
Global M&A trends in financial services: 2024 mid-year outlook
Published 12 Dec 2025 · pwc
FS M&A activity declined 15% in H1 2024 vs H1 2023, with deal values down 23%. Interest rate uncertainty drives selective bidding behaviour.
executive global -
Global M&A industry trends in real estate: 2024 mid-year outlook
Published 12 Dec 2025 · pwc
Global real estate M&A volumes declined 15% in H1 2024 vs H1 2023. High interest rates and valuation gaps drive market uncertainty.
executive global -
Global Insurance Run-off Survey 2024
Published 12 Dec 2025 · pwc
Insurance run-off market grows to $400bn+ globally. 67% of insurers now actively managing legacy portfolios vs 45% in 2022.
executive global -
Global M&A trends in financial services: 2024 outlook
Published 12 Dec 2025 · pwc
FS M&A faces headwinds from higher interest rates, regulatory scrutiny, and valuation gaps. Cross-border deals down 40% vs 2021 peak.
executive global -
Real Estate Transfer Tax: An international overview 17 countries at a glance
Published 12 Dec 2025 · pwc
Real estate transfer tax rates vary from 0% (Jersey) to 15% (UK SDLT). Belgium charges 10-12.5%, Germany 3.5-6.5%, France 5.8%.
executive global -
Global real estate investments: tax and legal aspects
Published 12 Dec 2025 · pwc
PwC guide covers tax and legal frameworks for cross-border real estate investment across multiple jurisdictions.
executive global -
Risk and Regulation
Published 12 Dec 2025 · kpmg
KPMG risk and regulation hub provides guidance across banking, insurance, and asset management sectors for compliance professionals.
functional_specialist global -
Banking transformation: The new agenda
Published 12 Dec 2025 · kpmg
Banking transformation requires new strategies as traditional cost-cutting reaches limits. Focus shifts to technology and operations.
executive global -
BBVA and OpenAI collaborate to transform global banking
Published 12 Dec 2025 · OpenAI
BBVA deploys ChatGPT Enterprise to all 120,000 employees in multi-year AI transformation partnership with OpenAI.
-
Mastercard and Kee Platforms Partner to Expand Embedded Financing for SMEs
Published 11 Dec 2025 · fintechnews.ae
Mastercard partners with Kee Platforms to expand embedded financing for SMEs with real-time credit access solutions.
-
Regulators announce plans to support growth of mutuals sector
Published 5 Dec 2025 · www.bankofengland.co.uk
The FCA and PRA announced measures to support the mutuals sector, including a new development unit and faster application processes. This aims to double the sector's size, impacting credit unions and building societies.
researcher uk -
Banking system stability: A global analysis of cybercrime laws
Published 1 Dec 2025 · arxiv.org
Cybercrime laws enhance banking stability by improving funding liquidity and reducing operational risk, especially in countries with strict penalties and strong enforcement.
researcher global -
Benchmarking LLM Agents for Wealth-Management Workflows
Published 1 Dec 2025 · arxiv.org
The study benchmarks LLM agents for wealth-management tasks, highlighting limitations in workflow reliability and autonomy impact.
researcher -
The rise of non-bank financial institutions: implications for monetary policy
Published 1 Dec 2025 · bis
NBFIs grow significantly, led by investment funds and hedge funds. Bond market expansion driven by surging government debt.
executive global -
Monopoly Pricing of Weather Index Insurance
Published 1 Dec 2025 · arxiv.org
The study models monopoly pricing of weather index insurance using a game-theoretic approach, highlighting how CNN-based designs can reduce basis risk and increase insurer profits.
researcher -
ARCADIA: Scalable Causal Discovery for Corporate Bankruptcy Analysis Using Agentic AI
Published 30 Nov 2025 · arxiv.org
ARCADIA, an AI framework, enhances causal discovery in corporate bankruptcy analysis, outperforming traditional models like NOTEARS and GOLEM.
researcher -
Chain-of-Query: Multi-Agent LLM Framework for SQL-Based Table Understanding
Published 30 Nov 2025 · arXiv
Multi-agent LLM framework improves SQL generation for table analysis. Addresses error propagation issues in current approaches.
functional_specialist global -
Global Banks' Spillovers to Emerging Markets: Macro to Micro Transmission
Published 30 Nov 2025 · arxiv.org
Global banks' net worth shocks affect emerging markets by appreciating local currencies and increasing capital flows, impacting investment and credit. This is crucial for emerging market economies.
researcher global -
Statistical modeling of SOFR term structure
Published 29 Nov 2025 · arxiv.org
The paper presents a statistical model for SOFR term structure, addressing the illiquidity and incompleteness of the derivatives market.
researcher -
When bricks meet bytes: does tokenisation fill gaps in traditional real estate markets?
Published 28 Nov 2025 · bis
Trading in tokenised properties rises 35% after natural disasters. Study finds tokenisation fills gaps in areas with lower prices and limited credit access.
executive global -
DeFi TrustBoost: Blockchain and AI for Trustworthy Decentralized Financial Decisions
Published 28 Nov 2025 · arxiv.org
The DeFi TrustBoost Framework combines blockchain and AI to enhance trust in decentralized financial decisions, focusing on confidentiality, compliance, and tamper-proof auditing.
researcher -
Dyna.Ai Positions Its Agentic AI to Advance Financial Services Beyond Pilots
Published 25 Nov 2025 · fintechnews.sg
Dyna.Ai's agentic AI aims to enhance financial services by moving beyond pilot projects to full AI autonomy, enabling significant returns for only 24% of institutions currently achieving this.
executive -
Scaling Conditional Autoencoders for Portfolio Optimization via Uncertainty-Aware Factor Selection
Published 24 Nov 2025 · arXiv Quantitative Finance
Research paper proposing a scalable conditional autoencoder framework with uncertainty-aware factor selection to estimate latent asset-pricing factors and improve portfolio optimization.
-
A Note on Recent Dynamics of Consumer Delinquency Rates
Published 24 Nov 2025 · www.federalreserve.gov
Credit card and auto loan delinquencies have increased post-pandemic, reaching levels not seen since the Great Financial Crisis. Lower-income households are particularly affected.
researcher us -
A calibrated model of debt recycling with interest costs and tax shields: viability under different fiscal regimes and jurisdictions
Published 23 Nov 2025 · arXiv Quantitative Finance
Debt recycling model shows homeowners can use home equity to accelerate mortgage repayment across 3 jurisdictions with tax shield benefits.
researcher -
Can Nash inform capital requirements? Allocating systemic risk measures
Published 21 Nov 2025 · arXiv Quantitative Finance
Game theory-based Nash allocation rule proposed for distributing systemic risk capital requirements across banks competing to reduce individual contributions.
functional_specialist -
You Can’t Fight Digital Fraud with One Hand Tied Behind Your Back
Published 20 Nov 2025 · fintechnews.sg
Matt DeLauro argues for unifying fraud and AML teams to combat financial crime effectively, highlighting SEON's platform as a solution.
executive -
Implications of Growth in ETFs: Evidence from Mutual Fund to ETF Conversions
Published 19 Nov 2025 · www.federalreserve.gov
ETF conversions from mutual funds improve market liquidity and reduce stock volatility, with $80 billion converted by 2024.
researcher global -
Banken zetten in op ai-agenten, maar echte doorbraak blijft uit
Published 17 Nov 2025 · bankcarriere.nl
Banks invest in AI agents for fraud detection, credit processing and customer service, but large-scale deployment remains limited.
executive -
CompressionAttack: Exploiting Prompt Compression as a New Attack Surface in LLM-Powered Agents
Published 17 Nov 2025 · arXiv
First framework exploits LLM prompt compression vulnerabilities. Compression modules optimized for efficiency create security gaps in agent systems.
functional_specialist global -
DeepKnown-Guard: A Proprietary Model-Based Safety Response Framework for AI Agents
Published 17 Nov 2025 · arXiv
DeepKnown-Guard enhances LLM safety with a 99.3% risk recall rate and a perfect 100% safety score on high-risk tests, offering a robust framework for AI security.
researcher global -
AI to Act as Virtual CFO and COO for SMEs, Says Ant Group Chairman
Published 17 Nov 2025 · fintechnews.sg
Ant Group Chairman Eric Jing announced AI's role as virtual CFO and COO for SMEs, enhancing payment integration and risk management.
executive -
How Data Quality Affects Machine Learning Models for Credit Risk Assessment
Published 14 Nov 2025 · arxiv.org
Data quality significantly impacts the accuracy of machine learning models in credit risk assessment. Controlled data corruption experiments show model robustness varies with data degradation severity.
researcher -
Synthetic Data-Driven Prompt Tuning for Financial QA over Tables and Documents
Published 14 Nov 2025 · arxiv.org
A new framework improves financial document analysis by using synthetic data to enhance prompt tuning for large language models, achieving better accuracy and robustness.
researcher -
SPEAR-MM: Selective Parameter Evaluation and Restoration via Model Merging for Efficient Financial LLM Adaptation
Published 12 Nov 2025 · arXiv
SPEAR-MM framework prevents catastrophic forgetting in financial LLMs, preserving general reasoning while enabling domain adaptation.
functional_specialist global -
Too Good to be Bad: On the Failure of LLMs to Role-Play Villains
Published 12 Nov 2025 · arXiv
LLMs struggle to role-play villains due to safety alignment, impacting their creative generation capabilities.
researcher global -
Reasoning Up the Instruction Ladder for Controllable Language Models
Published 12 Nov 2025 · arXiv
The study introduces VerIH, a dataset for training language models to prioritize instructions, enhancing model reliability and robustness against attacks.
researcher global -
MERaLiON-SER: Robust Speech Emotion Recognition Model for English and SEA Languages
Published 12 Nov 2025 · arXiv
MERaLiON-SER is a speech emotion recognition model for English and Southeast Asian languages, outperforming existing models in multilingual contexts.
researcher global -
A Cost-Benefit Analysis of On-Premise Large Language Model Deployment: Breaking Even with Commercial LLM Services
Published 11 Nov 2025 · arXiv
The paper provides a framework for evaluating when deploying large language models (LLMs) on-premise is cost-effective compared to commercial services, considering factors like hardware and operational costs.
functional_specialist global -
Two Heads are Better than One: Distilling Large Language Model Features Into Small Models with Feature Decomposition and Mixture
Published 11 Nov 2025 · arXiv
The paper introduces Cooperative Market Making (CMM), a framework for distilling large language model features into smaller models for financial trading, improving performance over existing methods.
researcher global -
Explaining the Unexplainable: A Systematic Review of Explainable AI in Finance
Published 11 Nov 2025 · arXiv
The paper reviews the use of Explainable AI (XAI) in finance, highlighting a reliance on post-hoc interpretability techniques like SHAP and feature importance analysis.
researcher global -
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Published 11 Nov 2025 · arXiv
SWE-Compass introduces a comprehensive benchmark for evaluating large language models (LLMs) in software engineering, covering 8 tasks, 8 scenarios, and 10 languages.
researcher global -
FinRpt: Dataset, Evaluation System and LLM-based Multi-agent Framework for Equity Research Report Generation
Published 11 Nov 2025 · arXiv
First academic framework for automating equity research reports using LLMs. FinRpt benchmark addresses data scarcity in financial report generation.
functional_specialist global -
Prudential Reliability of Large Language Models in Reinsurance: Governance, Assurance, and Capital Efficiency
Published 11 Nov 2025 · arXiv
Five-pillar framework for LLM reliability in reinsurance aligns with Solvency II, SR 11-7. Covers governance, data lineage, assurance controls.
functional_specialist global -
Minimal and Mechanistic Conditions for Behavioral Self-Awareness in LLMs
Published 10 Nov 2025 · arXiv
The study identifies conditions under which large language models (LLMs) exhibit behavioral self-awareness, raising safety concerns for AI evaluation.
researcher global -
LLM Output Drift: Cross-Provider Validation & Mitigation for Financial Workflows
Published 10 Nov 2025 · arXiv
Smaller LLMs (7B-8B params) show 100% output consistency vs larger models' drift. Study of 5 architectures reveals stability inversely correlates with size.
researcher global -
Making LLMs Reliable When It Matters Most: A Five-Layer Architecture for High-Stakes Decisions
Published 10 Nov 2025 · arXiv
Research identifies reliability gap in LLMs for high-stakes decisions vs verifiable tasks. Proposes 5-layer framework addressing AI-human bias loops.
researcher global -
AIA Forecaster: Technical Report - LLM-Based System for Judgmental Forecasting
Published 10 Nov 2025 · arXiv
LLM forecasting system combines agentic search, supervisor agents, and statistical calibration to counter behavioral biases in forecasting.
researcher global -
Know What You Don't Know: Uncertainty Calibration of Process Reward Models
Published 7 Nov 2025 · arXiv
The paper presents a method to calibrate process reward models (PRMs) for better accuracy in large language models, reducing inference costs while maintaining accuracy.
researcher global -
String Seed of Thought: Prompting LLMs for Distribution-Faithful and Diverse Generation
Published 7 Nov 2025 · arXiv
The paper introduces 'String Seed of Thought' (SSoT), a method to enhance LLMs' ability to generate diverse and distribution-faithful responses, crucial for applications like human-behavior simulation.
researcher global -
NMIXX: Domain-Adapted Neural Embeddings for Cross-Lingual eXploration of Finance
Published 7 Nov 2025 · arXiv
NMIXX improves cross-lingual financial text analysis by enhancing sentence embeddings, achieving significant performance gains on Korean financial benchmarks.
researcher global -
Multi-agent Coordination via Flow Matching
Published 7 Nov 2025 · arXiv
This paper introduces MAC-Flow, a framework for multi-agent coordination balancing rich behavior representation and real-time efficiency.
researcher global -
Grounded in Reality: Learning and Deploying Proactive LLM from Offline Logs
Published 7 Nov 2025 · arXiv
The paper introduces 'Learn-to-Ask', a framework for proactive dialogue agents using offline data, achieving superior performance to human experts in medical datasets.
researcher global -
Enterprise Deep Research: Steerable Multi-Agent Deep Research for Enterprise Analytics
Published 7 Nov 2025 · arXiv
EDR multi-agent system processes unstructured enterprise data using 4 specialized agents plus master planner for actionable insights.
functional_specialist global -
XBreaking: Understanding how LLMs security alignment can be broken
Published 7 Nov 2025 · arXiv
The paper introduces XBreaking, a method to exploit vulnerabilities in Large Language Models' (LLMs) security alignment through targeted noise injection.
researcher global -
What Matters in Data for DPO?
Published 7 Nov 2025 · arXiv
Research examines how preference data characteristics affect Direct Preference Optimization (DPO) performance in large language models.
functional_specialist global -
Query Generation Pipeline with Enhanced Answerability Assessment for Financial Information Retrieval
Published 7 Nov 2025 · arXiv
The paper introduces KoBankIR, a domain-specific IR benchmark for banking, using LLM-based query generation and enhanced answerability assessment, highlighting existing retrieval models' struggles with complex queries.
researcher global -
NVIDIA Nemotron Nano V2 VL: Vision-Language Model for Document Understanding and Video Comprehension
Published 7 Nov 2025 · arXiv
NVIDIA releases Nemotron Nano V2 VL vision-language model with improved document understanding and video comprehension vs Llama-3.1-Nemotron-Nano-VL-8B.
functional_specialist global -
AIRepr: An Analyst-Inspector Framework for Evaluating Reproducibility of LLMs in Data Science
Published 7 Nov 2025 · arXiv
AIRepr is a framework for assessing the reproducibility of LLM-generated data science workflows, enhancing transparency and reliability in human-AI collaboration.
functional_specialist global -
TimeCopilot: Open-Source Agentic Framework for Financial Time Series Forecasting
Published 7 Nov 2025 · arXiv
TimeCopilot launches as first open-source framework combining Time Series Foundation Models with LLMs for automated forecasting via unified API.
functional_specialist global -
Open Agent Specification (Agent Spec): A Unified Representation for AI Agents
Published 7 Nov 2025 · arXiv
The Open Agent Specification (Agent Spec) offers a unified framework for defining and evaluating AI agents across different systems, enhancing interoperability and reusability.
researcher global -
Generating Software Architecture Description from Source Code using Reverse Engineering and Large Language Model
Published 7 Nov 2025 · arXiv
The paper proposes a method to generate Software Architecture Descriptions (SADs) from source code using reverse engineering and large language models, reducing manual effort and improving system understanding.
researcher global -
From Observability Data to Diagnosis: An Evolving Multi-agent System for Incident Management in Cloud Systems
Published 7 Nov 2025 · arXiv
OpsAgent, a multi-agent system for cloud incident management, offers a cost-efficient, interpretable, and self-evolving solution, outperforming existing methods on the OPENRCA benchmark.
researcher global -
Conformal Information Pursuit for Interactively Guiding Large Language Models
Published 7 Nov 2025 · arXiv
The paper introduces Conformal Information Pursuit (C-IP) to improve query efficiency in Large Language Models (LLMs) by using conformal prediction sets to estimate uncertainty, outperforming traditional methods in predictive performance and query length.
researcher global -
TAMAS: Benchmarking Adversarial Risks in Multi-Agent LLM Systems
Published 7 Nov 2025 · arXiv
TAMAS introduces a benchmark to evaluate adversarial risks in multi-agent LLM systems, revealing significant vulnerabilities to attacks. This highlights the urgent need for improved defenses.
researcher global -
Optimizing Anytime Reasoning via Budget Relative Policy Optimization
Published 7 Nov 2025 · arXiv
The paper introduces AnytimeReasoner, a framework improving token efficiency in large language models by optimizing reasoning under varying token budgets using Budget Relative Policy Optimization (BRPO).
researcher global -
What Are the Facts? Automated Extraction of Court-Established Facts from Criminal-Court Opinions
Published 7 Nov 2025 · arXiv
The study demonstrates that automated methods can extract court-established facts from Slovak criminal court opinions with up to 99.5% accuracy when combining advanced regular expressions and large language models.
researcher eu -
Outbidding and Outbluffing Elite Humans: Mastering Liar's Poker via Self-Play and Reinforcement Learning
Published 7 Nov 2025 · arXiv
Solly, an AI agent, achieved elite human-level play in Liar's Poker using self-play and reinforcement learning, outperforming large language models.
researcher global -
Pluralistic Behavior Suite: Stress-Testing Multi-Turn Adherence to Custom Behavioral Policies
Published 7 Nov 2025 · arXiv
The Pluralistic Behavior Suite (PBSUITE) reveals that leading LLMs struggle with multi-turn adherence to custom behavioral policies, showing up to 84% failure rates in adversarial settings.
functional_specialist global -
Cognitive Edge Computing: A Comprehensive Survey on Optimizing Large Models and AI Agents for Pervasive Deployment
Published 7 Nov 2025 · arXiv
The paper surveys cognitive edge computing, focusing on optimizing large AI models for deployment on resource-constrained devices, highlighting model optimization, system architecture, and adaptive intelligence.
researcher global -
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Published 7 Nov 2025 · arXiv
The paper introduces a framework to create a verifiable knowledge base, SciencePedia, using a Long Chain-of-Thought approach, enhancing scientific reasoning transparency and accuracy.
researcher global -
DeepForgeSeal: Latent Space-Driven Semi-Fragile Watermarking for Deepfake Detection Using Multi-Agent Adversarial Reinforcement Learning
Published 7 Nov 2025 · arXiv
DeepForgeSeal introduces a watermarking framework using Multi-Agent Adversarial Reinforcement Learning to enhance deepfake detection, outperforming existing methods by over 4.5% on CelebA and 5.3% on CelebA-HQ benchmarks.
researcher global -
AI Through the Human Lens: Investigating Cognitive Theories in Machine Psychology
Published 7 Nov 2025 · arXiv
The study explores how Large Language Models (LLMs) mimic human cognitive patterns, revealing implications for AI transparency and ethical deployment.
researcher global -
BudgetMem: Learning Selective Memory Policies for Cost-Efficient Long-Context Processing in Language Models
Published 7 Nov 2025 · arXiv
BudgetMem reduces memory usage by 72.4% with only a 1.0% F1 score degradation in long-context processing, enabling efficient deployment on modest hardware.
researcher global -
iTool: Reinforced Fine-Tuning with Dynamic Deficiency Calibration for Advanced Tool Use
Published 7 Nov 2025 · arXiv
The iTool method improves large language models by 13.11% using reinforced fine-tuning and dynamic deficiency calibration, outperforming larger models in complex tasks.
researcher global -
TeaRAG: A Token-Efficient Agentic Retrieval-Augmented Generation Framework
Published 7 Nov 2025 · arXiv
TeaRAG improves token efficiency in Retrieval-Augmented Generation by compressing retrieval content and reasoning steps, enhancing Exact Match by up to 4% while reducing token output by over 59%.
functional_specialist global -
LiveStar: Live Streaming Assistant for Real-World Online Video Understanding
Published 7 Nov 2025 · arXiv
LiveStar improves online video understanding with a 19.5% increase in semantic correctness and a 12.0% FPS boost, offering real-time responsiveness.
functional_specialist global -
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search
Published 7 Nov 2025 · arXiv
The paper introduces Adaptive Branching Monte Carlo Tree Search (AB-MCTS) to enhance LLM inference by dynamically choosing between expanding or revisiting candidate responses based on feedback, outperforming existing methods.
researcher global -
Large language models as uncertainty-calibrated optimizers for experimental discovery
Published 7 Nov 2025 · arXiv
Training large language models with uncertainty-aware objectives enhances their reliability in experimental optimization, doubling discovery rates in pharmaceutical synthesis.
researcher global -
From pilot to practice: How BBVA is scaling AI across the organization
Published 6 Nov 2025 · openai.com
BBVA has scaled AI to 11,000 employees, saving ~3 hours per employee weekly and achieving up to 80% efficiency improvements in workflows.
researcher -
AI Agentic Vulnerability Injection And Transformation with Optimized Reasoning
Published 6 Nov 2025 · arXiv
Academic research on automated vulnerability detection using deep learning models. Limited practical banking/financial services applications.
functional_specialist global -
HugAgent: Benchmarking LLMs for Simulation of Individualized Human Reasoning
Published 6 Nov 2025 · arXiv
HugAgent introduces a benchmark for evaluating large language models' ability to simulate individualized human reasoning, highlighting gaps in current AI models.
researcher global -
First is Not Really Better Than Last: Evaluating Layer Choice and Aggregation Strategies in Language Model Data Influence Estimation
Published 6 Nov 2025 · arXiv
Middle attention layers in language models provide better influence estimation than first layers, challenging previous assumptions. New aggregation methods improve performance.
researcher global -
Internal World Models as Imagination Networks in Cognitive Agents
Published 6 Nov 2025 · arXiv
The study explores how imagination networks in humans differ from those in large language models (LLMs), revealing significant differences in network clustering and centrality correlations.
researcher global -
Trustworthiness Calibration Framework for Phishing Email Detection Using Large Language Models
Published 6 Nov 2025 · arXiv
The study introduces the Trustworthiness Calibration Framework (TCF) to evaluate phishing email detectors using large language models, highlighting GPT-4's superior trust profile.
researcher global -
Activation-Informed Merging of Large Language Models
Published 6 Nov 2025 · arXiv
Activation-Informed Merging (AIM) enhances large language model performance by up to 40% using activation-space information.
researcher global -
ProRefine: Inference-Time Prompt Refinement with Textual Feedback
Published 6 Nov 2025 · arXiv
ProRefine enhances AI prompt accuracy by 3-37% using inference-time optimization, enabling smaller models to perform like larger ones.
researcher global -
TOBUGraph: Knowledge Graph-Based Retrieval for Enhanced LLM Performance Beyond RAG
Published 6 Nov 2025 · arXiv
TOBUGraph enhances LLM retrieval by using knowledge graphs to improve precision and recall, outperforming RAG methods in real-world applications.
researcher global -
The State of AI: Global Survey 2025
Published 5 Nov 2025 · www.mckinsey.com
Most organizations are still piloting AI, with 88% using it in at least one function, but only 39% report enterprise-level EBIT impact. High performers focus on growth and innovation.
researcher -
$370 Billion Profit Potential for Retail Banks via AI by 2030
Published 5 Nov 2025 · www.bcg.com
Retail banks could increase profits by $370 billion by 2030 through AI adoption, according to BCG.
executive -
POLIS-Bench: Towards Multi-Dimensional Evaluation of LLMs for Bilingual Policy Tasks in Governmental Scenarios
Published 4 Nov 2025 · arXiv
POLIS-Bench introduces a comprehensive evaluation framework for LLMs in bilingual governmental policy tasks, highlighting a performance hierarchy among models.
researcher global -
Prioritize Economy or Climate Action? Investigating ChatGPT Response Differences Based on Inferred Political Orientation
Published 4 Nov 2025 · arXiv
The study reveals that ChatGPT's responses align with inferred political views, showing varied reasoning and vocabulary. This suggests potential bias in AI outputs.
researcher global -
Measuring what Matters: Construct Validity in Large Language Model Benchmarks
Published 3 Nov 2025 · arXiv
The paper highlights the importance of construct validity in evaluating large language models (LLMs) and offers eight recommendations to improve benchmark development.
researcher global -
2025 List of Global Systemically Important Banks (G-SIBs) - Financial Stability Board
Published 1 Nov 2025 · www.fsb.org
The Financial Stability Board has released the 2025 list of Global Systemically Important Banks (G-SIBs), highlighting banks crucial to global financial stability.
researcher global -
Integrating contagion risk into the 2025 EU-wide stress test: a system-wide analysis with amplification effects between banks and non-banks
Published 1 Nov 2025 · www.ecb.europa.eu
The 2025 EU-wide stress test incorporates contagion risk, revealing a 29 basis point CET1 ratio depletion and highlighting significant impacts on investment funds and banks with limited hedging capabilities.
researcher eu -
Systemic risks in linkages between banks and the non-bank financial sector
Published 1 Nov 2025 · www.ecb.europa.eu
Euro area banks' linkages with non-bank financial intermediaries (NBFIs) pose systemic risks, particularly through short-term liabilities and leveraged credit provision. These connections could lead to asset price shocks and funding outflows.
researcher eu -
Separate the Wheat from the Chaff: Winnowing Down Divergent Views in Retrieval Augmented Generation
Published 1 Nov 2025 · arXiv
WinnowRAG enhances retrieval-augmented generation by filtering irrelevant documents, improving accuracy without model fine-tuning.
researcher global -
FSB publishes 2025 G-SIB list - Financial Stability Board
Published 1 Nov 2025 · www.fsb.org
The Financial Stability Board (FSB) has released the 2025 list of Global Systemically Important Banks (G-SIBs), crucial for regulatory compliance and risk management in banking.
researcher global -
EncouRAGe: Evaluating RAG Local, Fast, and Reliable
Published 31 Oct 2025 · arXiv
EncouRAGe is a Python framework for evaluating Retrieval-Augmented Generation (RAG) systems, highlighting the underperformance of RAG compared to Oracle Context and the superior results of Hybrid BM25.
researcher global -
Simulating Misinformation Vulnerabilities With Agent Personas
Published 31 Oct 2025 · arXiv
The study uses agent-based simulations with Large Language Models to assess misinformation vulnerabilities, finding mental schemas more influential than professional backgrounds in interpreting misinformation.
researcher global -
JPMorgan Chase’s Derek Waldron on AI and banking
Published 29 Oct 2025 · McKinsey & Company
JPMorgan Chase's AI transformation, led by Derek Waldron, leverages a $18 billion tech budget and LLM Suite to democratize AI use among employees, enhancing productivity and innovation.
executive us -
Adaptive Testing for LLM Evaluation: A Psychometric Alternative to Static Benchmarks
Published 26 Oct 2025 · arXiv
ATLAS, an adaptive testing framework, reduces evaluation items by 90% while maintaining precision, challenging static benchmarks in LLM evaluation.
researcher global -
OCC and FDIC Withdraw ‘Overly Restrictive’ Guidance
Published 15 Oct 2025 · www.pymnts.com
The OCC and FDIC have withdrawn guidance on leveraged lending, citing it as overly restrictive.
researcher us -
OCC Interpretations and Actions October 2025
Published 1 Oct 2025 · Office of the Comptroller of the Currency
OCC publishes October 2025 regulatory interpretations and enforcement actions affecting national banks and federal savings associations.
functional_specialist -
Payment Innovation: Real-Time Systems Shape Industry Future
Published 28 Sept 2025 · Fintech Magazine
High-level piece on how real-time payment systems are reshaping the future of the payments industry and broader financial services.
executive global -
Banks' regulatory risk tolerance
Published 4 Sept 2025 · www.bis.org
Banks' regulatory risk tolerance increased post-GFC, with higher management buffer targets and speeds of reversion, especially in banks with volatile buffer shocks. High-RRT banks cut lending when buffers deplete, impacting the real economy.
researcher -
Financial stability implications of tokenisation
Published 28 Aug 2025 · www.bis.org
Tokenisation, using distributed ledger technology, offers potential benefits like efficiency and transparency but poses financial stability risks, including liquidity mismatches and operational fragilities.
researcher -
Advancing in tandem - results of the 2024 BIS survey on central bank digital currencies and crypto
Published 22 Aug 2025 · www.bis.org
The 2024 BIS survey reveals that 91% of central banks are exploring CBDCs, with wholesale CBDCs at more advanced stages than retail ones.
researcher global -
Agent Factory: The new era of agentic AI—common use cases and design patterns
Published 13 Aug 2025 · azure.microsoft.com
Agentic AI transforms enterprise automation by enabling agents to reason, act, and collaborate, bridging the gap between knowledge and outcomes. Azure AI Foundry provides a unified platform to develop and deploy these agents efficiently.
executive -
What is RegTech?
Published 11 Aug 2025 · McKinsey & Company
RegTech, or regulatory technology, helps financial institutions manage compliance and risk. In 2024, banks paid $19.3 billion in penalties, highlighting the need for effective RegTech solutions.
executive global -
Public support for bank resolution
Published 30 Jul 2025 · www.bis.org
Public support for bank resolution should be credibly funded and used only as a last resort to maintain financial stability. Jurisdictions must codify policies to recoup public support and ensure governance to preserve social legitimacy.
researcher -
Payments fraud prevention in the global payments industry
Published 30 Jul 2025 · McKinsey & Company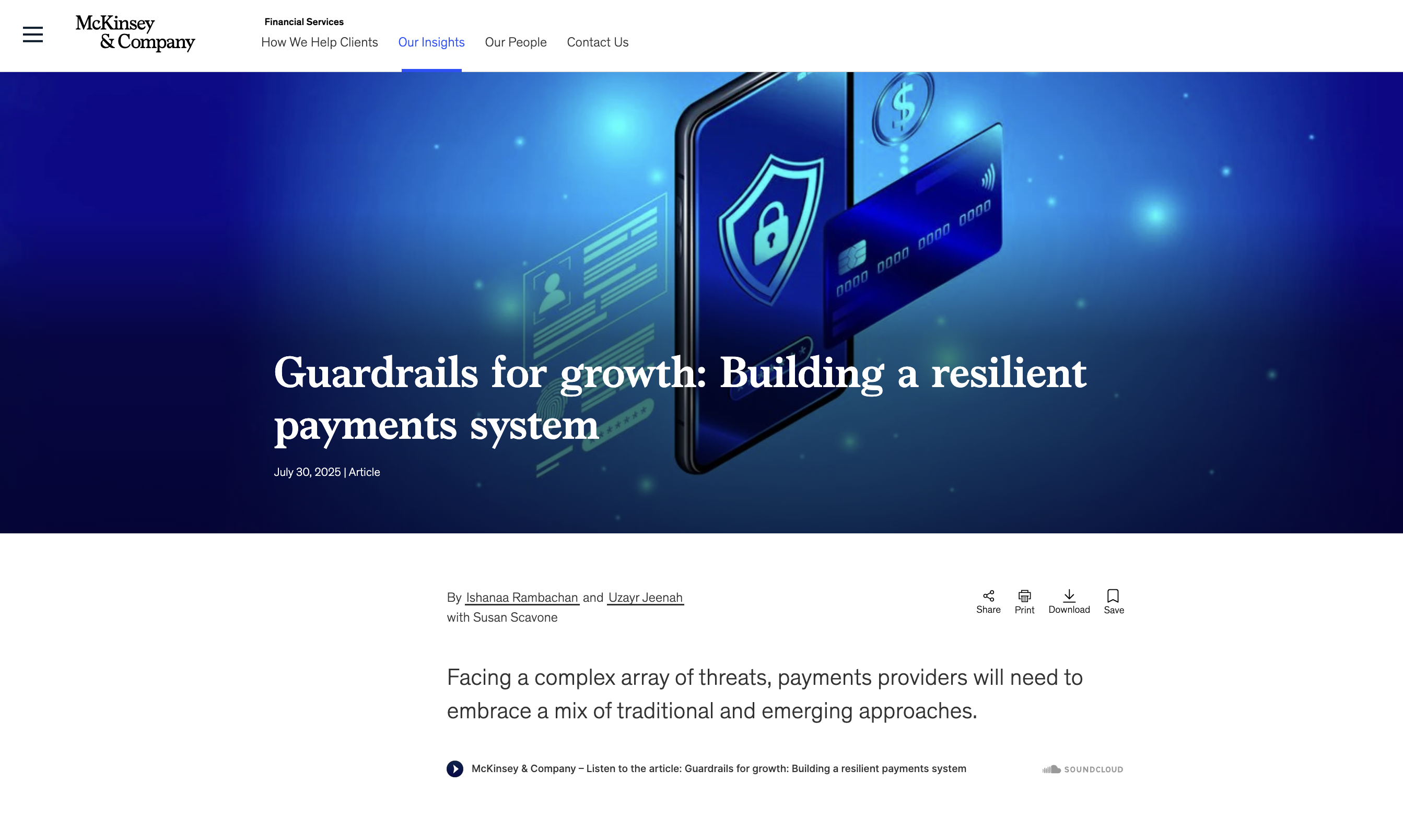
The global payments industry, valued at $2.4 trillion, faces growing fraud risks, with online payment fraud expected to exceed $362 billion by 2028. Payments providers must balance fraud prevention with customer experience.
executive global -
AI Agent Team Automates Development Tasks Using Claude Code Subagents
Published 25 Jul 2025 · medium.com
Developer spent 30 days testing Claude Code subagents for automated development tasks with mixed results and key learnings.
-
Integrating balance sheet policy into monetary policy conditions
Published 25 Jul 2025 · www.bis.org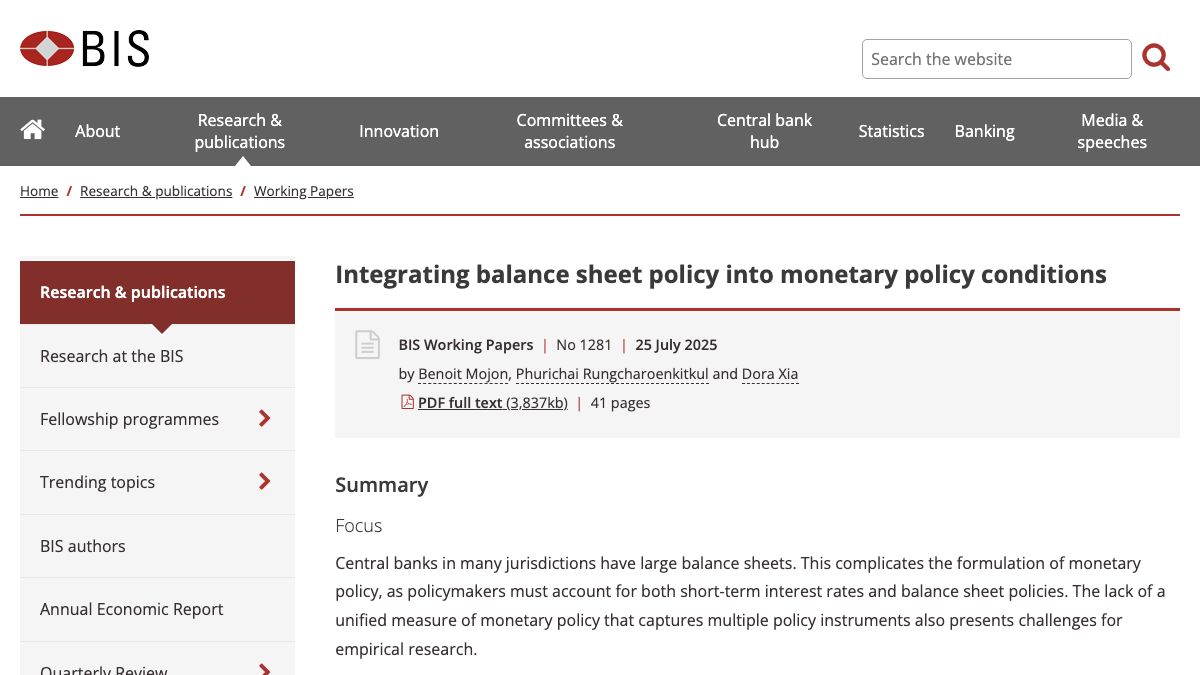
The paper introduces a new Monetary Policy Conditions Index (MCI) that integrates conventional and unconventional tools, providing insights into balance sheet policy effects beyond the effective lower bound.
researcher -
The future of AI in the insurance industry
Published 15 Jul 2025 · McKinsey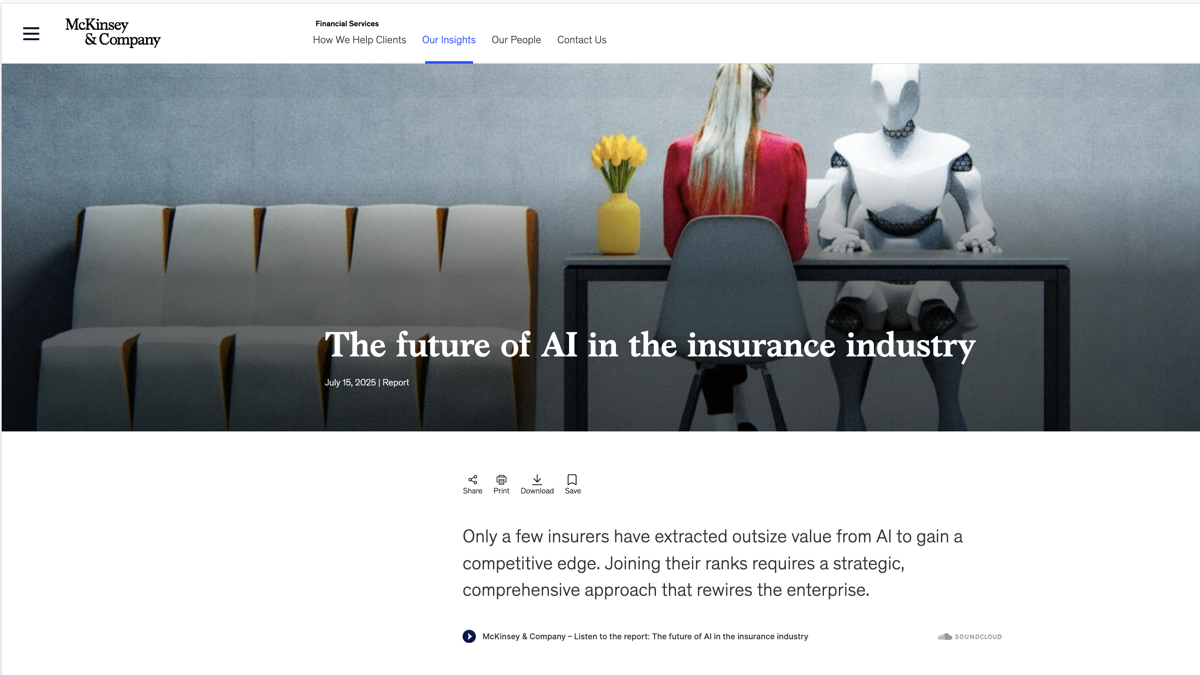
AI is transforming the insurance industry, with leaders achieving 6.1 times the TSR of laggards. Insurers must integrate AI enterprise-wide to remain competitive.
executive global -
CBDC and banks: disintermediating fast and slow
Published 8 Jul 2025 · www.bis.org
The introduction of a retail CBDC could lead to both slow and fast disintermediation, impacting financial stability. A holding limit on CBDC can mitigate these risks.
researcher -
Central bank and media sentiment on central bank digital currency: an international perspective
Published 8 Jul 2025 · www.bis.org
Central bank sentiment on digital currencies influences media sentiment and impacts cryptocurrency and equity markets. Positive central bank sentiment negatively affects cryptocurrency returns and banking stocks.
researcher global -
Incorporating physical climate risks into banks' credit risk models
Published 7 Jul 2025 · www.bis.org
The BIS paper proposes integrating physical climate risks into banks' credit risk models using an extended Vasicek model. This approach helps banks manage climate risks in credit portfolios.
researcher global -
How to succeed in the role of chief risk officer (CRO)
Published 2 Jul 2025 · McKinsey & Company
New CROs should adopt six key habits to succeed, including establishing a clear risk strategy and fostering strong relationships with the board and supervisors.
executive global -
Natural Language Reinforcement Learning
Published 28 May 2025 · arXiv
NLRL replaces scalar value functions with linguistic narratives, achieving 40% better win rates (0.4→0.9) vs traditional RL in game environments.
-
Identification requirements at financial enterprises - Dutch Data Protection Authority guidance
Published 9 Apr 2025 · autoriteitpersoonsgegevens.nl
Banks must verify ID using unedited copies (no watermarks/blackouts). 5-year retention required. Remote checks need photo/video selfies.
functional_specialist eu -
AI bij verzekeraars: kansen en risico’s
Published 27 Mar 2025 · www.dnb.nl
De Nederlandsche Bank's 2024 study reveals that 15 out of 36 insurers use AI, mainly for fraud detection and risk assessment. The AI Act, effective from August 2024, guides AI application in insurance.
researcher -
Automating 90% of finance and legal work with agents
Published 20 Mar 2025 · openai.com
Hebbia's Matrix platform automates 90% of finance and legal work using AI agents, achieving 92% accuracy in complex tasks.
researcher -
Why Do Multi-Agent LLM Systems Fail?
Published 13 Mar 2025 · arXiv
The paper explores the reasons behind the failure of multi-agent large language model (LLM) systems, focusing on coordination and communication issues.
researcher global -
Nubank elevates customer experiences with OpenAI
Published 6 Mar 2025 · openai.com
Nubank uses OpenAI's AI solutions to enhance customer experiences and internal efficiency, serving over 114 million customers across Latin America.
researcher latam -
SoFi Aims to Raise $1.5 Billion to Fund Business Opportunities
Published 15 Jan 2025 · www.pymnts.com
SoFi plans to raise $1.5 billion to expand its business operations, indicating growth ambitions in digital banking.
researcher us -
AI agents for cash management in payment systems
Published 26 Nov 2024 · bis
ChatGPT successfully manages bank liquidity in RTGS payment systems without specialized training, replicating key cash management practices.
engineer global -
The rise of tokenised money market funds
Published 26 Nov 2024 · bis
Tokenised money market funds emerge as fast-growing crypto collateral offering money market returns with regulatory protections on blockchains.
executive global -
What Is Agentic AI?
Published 22 Oct 2024 · NVIDIA Blog
Agentic AI autonomously solves complex, multi-step problems using sophisticated reasoning and iterative planning, enhancing productivity across industries.
functional_specialist global -
New Credit Facility Enhances Financial Flexibility
Published 3 Oct 2024 · openai.com
OpenAI secures a $4 billion credit facility from major banks, enhancing its financial flexibility with over $10 billion in liquidity.
researcher global -
Latest Data Science Trends Reshaping The Industry in 2024
Published 30 Jul 2024 · Moringa School
Data science in 2024 will be shaped by AI, big data, and interdisciplinary integration, impacting career opportunities and industry practices.
functional_specialist global -
Artificial intelligence: a central bank’s view
Published 4 Jul 2024 · www.ecb.europa.eu
AI adoption is rising, with nearly 75% of organizations using AI, but only 8% apply it across five or more functions. This suggests early-stage integration, impacting productivity and monetary policy.
researcher -
10 Trends Defining Growth for Financial Services Businesses in 2024
Published 25 Jun 2024 · Propello Cloud
Digital transformation and data-driven insights are reshaping financial services, with fintechs challenging traditional banks. Open banking and compliance with regulations like PSD2 and ESG are crucial. AI and cybersecurity are key focus areas.
executive global -
8 Top Computer Science Trends (2024 & 2025)
Published 10 Jun 2024 · Exploding Topics
AI and quantum computing are reshaping computer science, with AI aiding 18% of research papers and quantum computing promising breakthroughs despite current limitations.
functional_specialist global -
What is Digital Transformation & Why It's Important for Businesses?
Published 1 Feb 2024 · Imaginovation
Digital transformation integrates digital technology into business operations, driving competitive advantage and customer value. It is crucial for businesses to stay relevant in a technology-driven world.
executive global -
Agentic Enterprise 2028: A Blueprint for Cost Savings, Job Creation, and Faster Growth Through Agentic AI
Published 15 Oct 2023 · Deloitte
Deloitte's report outlines how Agentic AI can drive cost savings, job creation, and growth by 2028. BFSI sectors can leverage AI for efficiency and innovation.
executive global -
Regulators announce plans to support growth of mutuals sector
Published 12 Oct 2023 · www.fca.org.uk
The FCA has announced plans to support the growth of the mutuals sector, aiming to enhance market integrity and promote competition.
executive uk -
FCA consults on reducing late fees for regulatory returns
Published 10 Oct 2023 · www.fca.org.uk
The FCA is consulting on reducing late fees for regulatory returns to ease financial burdens on firms. This initiative aims to enhance compliance and market integrity.
researcher uk -
Scammers and Fake Banks
Published 1 Oct 2023 · www.fdic.gov
The FDIC warns about scammers creating fake bank websites and apps to steal personal information. Verify bank legitimacy using FDIC's BankFind tool.
researcher us -
ISDA/SIFMA/IIB SBS Comment Letters to SEC – International Swaps and Derivatives Association
Published 22 Mar 2022 · www.isda.org
The ISDA, SIFMA, and IIB submitted comment letters to the SEC regarding security-based swaps regulations.
researcher us -
Insurance 2030—The impact of AI on the future of insurance
Published 12 Mar 2021 · McKinsey
AI will transform insurance by 2030, shifting from 'detect and repair' to 'predict and prevent'. This will impact claims, distribution, and underwriting.
executive global -
Application of the Prepaid Access Rule to Bank-Controlled Programs
Published 8 Jun 2012 · www.fincen.gov
FinCEN clarifies that banks cannot be designated as providers of prepaid access under MSB regulations, impacting companies distributing bank-issued prepaid cards.
researcher us